
One of the goals of this blog is to discuss various approaches to forecasting asset returns taken from both the economics and machine learning fields. Before diving into specific models and techniques, however, I begin by discussing the issue of noise in financial markets.
Let’s start by decomposing returns into expected and unexpected returns. We have
![[1]\hspace{0.5cm} R_t = E_{t-1}(R_t) + \epsilon_t](https://s0.wp.com/latex.php?latex=%5B1%5D%5Chspace%7B0.5cm%7D+R_t+%3D+E_%7Bt-1%7D%28R_t%29+%2B+%5Cepsilon_t&bg=ffffff&fg=333333&s=0&c=20201002)
where 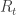

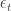
The first thing to notice is that 

![[2]\hspace{0.5cm} \mu_t = \beta x_t + \nu_t](https://s0.wp.com/latex.php?latex=%5B2%5D%5Chspace%7B0.5cm%7D+%5Cmu_t+%3D+%5Cbeta+x_t+%2B+%5Cnu_t&bg=ffffff&fg=333333&s=0&c=20201002)
where I assume a zero intercept for simplicity and 


The first reason is that while realized returns are an unbiased estimator of expected returns, the variation in 

The second reason, from Elton (1999), is that some of the return surprises 
There are periods longer than 10 years during which stock market realized returns are on average less than the risk-free rate (1973 to 1984). There are periods longer than 50 years in which risky long-term bonds on average underperform the risk free rate (1927 to 1981). Having a risky asset with an expected return above the riskless rate is an extremely weak condition for realized returns to be an appropriate proxy for expected returns, and 11 and 50 years is an awfully long time for such a weak condition not to be satisfied.
More recently, if we have a data set that covers, say, only the last 10-15 years, the Great Recession will have a very strong influence on most attempts to construct a forecasting model.
What can we do about the situation? One idea is to try to remove the noise ex-post from our sample of historical returns. In places like IEEE conference proceedings, you sometimes see papers that apply smoothing techniques developed in engineering applications to filter noise from returns. Robust M-estimators from the statistics literature can also be used to identify influential observations. Finally, we might try examining the news during periods of unusually large return magnitudes in order to determine whether the returns represent expected or unexpected shocks. Of course, all of these methods are imperfect since it is extremely difficult to determine what was unexpected even with the benefit of hindsight.
Another idea is to obtain a proxy for expected returns that does not rely on realized returns. The leading approach, in the context of stocks, is the implied cost of capital (ICC), which can be thought of as essentially the internal rate of return (IRR) of the dividend discount model. For a given stream of expected future dividends, a lower stock price implies that the ICC is higher. Of course, expected dividends going years into the future are unobservable. Therefore most models use analyst earnings forecasts for the first few years together with some terminal value assumption for the years beyond . Since the ICC should contain much less noise than realized returns, the approach may allow for more precise inferences about which variables can forecast the market. Li, Ng, and Swaminathan (2013) provide a recent example of the ICC approach to predicting stock market returns. A cautionary point is that there are many possible ways to construct and estimate the ICC. The fact that we don’t know the true model introduces additional uncertainty to our estimate.
So while we usually end up using realized returns as our proxy for expected returns, the decomposition in equation [1] is useful keep in the back of our minds to remind us that they are not the same thing and that sometimes we will want to take another approach.
References
Elton, E. 1999. Expected return, realized return, and asset pricing tests. Journal of Finance, 54.4, 1199-1220.
Li, Y., D. Ng, and B. Swaminathan. 2013. Predicting market returns using aggregate implied cost of capital. Journal of Financial Economics, 110.2, 419-436.
