
Data snooping is pervasive in financial research, both in academia and in industry. In my experience, the level of awareness about data snooping varies widely among practitioners. All too often, however, huge amounts of time and effort are wasted by following a flawed research process due to misunderstanding about this critical issue. In this post, I give a non-technical introduction of what it is, how it can occur, and what can be done about it. (Economists often use the term data mining to mean the same thing. However, since there are now respectable conferences in data mining or knowledge discovery, I use the term data snooping here with its clearly negative connotations.)
Hal White (2000) defined the term as follows:
Data snooping occurs when a given set of data is used more than once for purposes of inference or model selection. When such data reuse occurs, there is always the possibility that any satisfactory results obtained may simply be due to chance rather than to any merit inherent in the method yielding the results.
In machine learning terms, this means that data used for training (even indirectly) can no longer be used to provide an unbiased assessment of learning performance.
How does data snooping occur? In a non-experimental science, we have only one realization of history for a given period of time. In the context of investments, this fact makes it almost inevitable that we reexamine the same historical data. Unfortunately, as we repeatedly try different models to explain or predict the data, the probability of finding one that is apparently successful will become very close to 100% even if the models are completely useless.
This data reuse can occur both at the level of the individual researcher as well as collectively. Very often a researcher will look at previous research done by others and get an idea of what works and doesn’t work in the data. He will then try to make further improvements and conduct a series of trials himself until he finds one that is satisfactory. Too often, however, we only see the final product of this process. Hence the old saying “I never met a backtest I didn’t like.” Needless to say, no reliable inference can be made from looking at the output of such a process. As I discussed in a previous post, even the use of pseudo-out-of-sample tests will not provide much protection against a determined data snooper.
Yaser Abu-Mostafa at Caltech provides a nice discussion of data snooping in his lectures on learning from data. He notes that in order to assess the impact of data snooping, one needs to quantify the penalty for model complexity correctly. He emphasizes that the effective VC dimension for the series of trials will not be that of the last model that succeeded, but of the entire union of models that could have been used depending on the outcomes of different trials. The effective VC dimension also needs to account for all hypotheses that were considered (and mostly rejected) by everyone else in the research process. (The Vapnik-Chervonenkis or VC dimension is a way of measuring the complexity of a class of functions. The important thing to know here is that higher VC dimension, beyond a certain level, will make expected out-of-sample error worse.)
Furthermore, data reuse occurs even if we only casually look at the data before doing formal testing. Suppose, for example, you are building a model to predict financial market crises. You haven’t tested any models on the data yet, but like any investment analyst you read the newspapers and are aware that banks had something to do with the Great Recession. It seems quite sensible then to include some measures of the banking sector in your model. But would you have formulated the same models to test without having knowledge of what transpired over the past couple of years? In 2009, a colleague of mine asked Mark Carney, the governor of the Bank of Canada, (in a non-private forum) how the bank’s in-house models performed in forecasting the financial crisis. Carney replied that the BoC had several models, but none included the banking sector in any detail. This state of affairs was hardly unique among central banks around the world.
The statistician’s admonition to not look at the data before formulating a hypothesis or choosing a model sounds quite backwards to most practitioners. However, classical inference requires this in order to avoid data snooping. Ed Leamer (1978) refers to such post-data model construction as Sherlock Holmes inference. (In A Study in Scarlet, Holmes warns that “it is a capital mistake to theorize before you have all the evidence.”) By looking at the data before selecting a model, we compromise the ability of the same data to assess it. However, as Leamer neatly observes, Holmes, unlike most of us, has “the luxury of the ultimate extra bit of data – the confession.” The whole issue of whether Sherlock Holmes inference is legitimate is beyond the scope of this discussion and is related to the subject of bayesian inference.
So what can we do about data snooping? Simply put, there are two fundamental approaches. The first is to avoid data snooping. We maintain a strict separation of data used to develop hypotheses and train models from the data used to test them. However, as we discussed, there are rarely any new financial market data uncontaminated by data snooping with which to test models. High frequency data may be an exception since we can sometimes get a sufficient quantity of new data after a model has been finalized.
The second approach is to account for data snooping. White (2000) introduced a method for quantifying the data snooping bias and accounting for the universe of trading rules that are examined. A future post will cover this and more recent approaches in greater detail. The basic intuition, however, goes back to the Bonferroni method.
Suppose that we are testing a null hypotheses 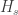






These methods give the practitioner a way to account for data snooping. However, they do have drawbacks. First, since data snooping can take place collectively among all researchers and even from background knowledge of financial history, it can be difficult to correctly specify the space of hypotheses that has been examined. Second, the true dependence structure between tests is unknown and must be estimated from the data.
In conclusion, data snooping presents great challenges to researchers in financial markets. It is very difficult to avoid and challenging to properly account for. However, ignoring the issue can lead to misplaced optimism about the future performance of trading strategies and a corresponding misallocation of capital.
References
Abu-Mostafa, Y. Learning from data – online course. https://work.caltech.edu/telecourse.html
Leamer, E. 1978. Ad hoc inference with nonexperimental data.
White, H. 2000. A reality check for data snooping. Econometrica, 68.5, 1097-1126.

Thank you so much for this beautiful blog.It helped me a lot in understanding data snooping