
When doing data analysis, we have come to regard two as the threshold that a t-statistic must clear in order to declare a variable statistically significant. As most readers will know, this critical value ensures a 5% level of significance given a reasonably large number of observations. In the context of investments, we might be looking at whether a variable such as a firm’s book-to-market ratio is related to its stock returns or whether the time series of returns from some trading strategy or portfolio manager is reliably different from zero.
In my previous post on data snooping, I discussed some of the problems that arise from testing multiple hypotheses. In particular, if we conduct a large number of tests, we are very likely to find relationships or patterns in the data simply by chance. Yet, we do this all the time in finance when developing trading strategies or evaluating investment managers. So while two might be the appropriate threshold for a t-statistic when conducting a single test, it will leave us with too many strategies or managers bound to disappoint when we conduct a wide search.
Given a time series of returns, we could test the null hypothesis that the trading strategy has zero excess returns by calculating the t-statistic as 

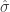

Since the Sharpe Ratio is simply 
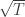
Now let’s make the main argument more concrete. Suppose that we test 


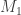







Define the family-wise error rate (FWE) as the probability of having at least one false discovery:

Now suppose M = 1 (that is, we conduct exactly one test) and set the level of significance to the usual 5%. Then 
![FWE = [1 - (1 - 0.05)^{20}] = 0.6415](https://s0.wp.com/latex.php?latex=FWE+%3D+%5B1+-+%281+-+0.05%29%5E%7B20%7D%5D+%3D+0.6415&bg=ffffff&fg=333333&s=0&c=20201002)
So the chance of making a false discovery (e.g. a trading strategy or manager that we mistakenly believe has true alpha, but in fact does not) jumps to nearly two-thirds. If we increase the number of tests to M = 100, then we have a near certainty of making a false discovery:
![FWE = [1 - (1 - 0.05)^{100}] = 0.9941](https://s0.wp.com/latex.php?latex=FWE+%3D+%5B1+-+%281+-+0.05%29%5E%7B100%7D%5D+%3D+0.9941&bg=ffffff&fg=333333&s=0&c=20201002)
The Bonferroni adjustment, which I mentioned in a previous post, is one way in which to control the FWE. Suppose we want to ensure that the 


![FWE = [1 - (1 - 0.05/20)^{20}] = 0.0488](https://s0.wp.com/latex.php?latex=FWE+%3D+%5B1+-+%281+-+0.05%2F20%29%5E%7B20%7D%5D+%3D+0.0488&bg=ffffff&fg=333333&s=0&c=20201002)
![FWE = [1 - (1 - 0.05/100)^{100}] = 0.0488](https://s0.wp.com/latex.php?latex=FWE+%3D+%5B1+-+%281+-+0.05%2F100%29%5E%7B100%7D%5D+%3D+0.0488&bg=ffffff&fg=333333&s=0&c=20201002)
In both cases, Bonferroni successfully keeps the FWE below 5%, which is what we wanted. However, this success comes at a price. For M=100, we now require each test to have a p-value smaller than 
What does this mean for the t-statistic hurdle when evaluating the returns for some investment strategy? The t-statistic (defined earlier) follows a t-distribution with T-1 degrees of freedom under the null (under some statistical assumptions on the returns that we won’t go into). Suppose we have T = 120 observations and use a two-tailed test. For a significance level of 0.05, the critical value is 1.9801 so our magic number of two works fine. For a significance level of 0.05/100 = 0.0005, the critical value becomes 3.5791. (Matlab has a function tinv(P,V) to calculate the inverse cumulative distribution function for student’s t where P is the probability and V is the degrees of freedom. The expression tinv(1-0.0005/2, 119) returns 3.5791.) This higher threshold, however, is very stringent and will very likely result in our missing trading strategies that actually do have alpha (that is, missed discoveries).
An improved method to control FWE is given by Holm (1979). The key insight is that Bonferroni doesn’t use all the information present in the collection of test statistics. We start by ordering the p-values for the M tests such that


Now define the function 
Start with the first test (k=1) and compare it’s p-value 
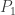

Both Bonferroni and Holm are methods to eliminate any false discoveries regardless of the number of tests and therefore may be too stringent for our purposes. Having one false discovery out of say twenty rejections is not nearly as bad as having one out of five. Furthermore, we might prefer utilizing many trading strategies, a few of which may be useless, to not finding any trading strategies because we set the statistical bar too high. The next post will discuss how to use this idea to control the proportion of false discoveries in the tests that we reject.
Summary
Multiple testing occurs frequently in finance when we examine many trading strategies or portfolio managers in an attempt to identify those with true alpha. We show that if we use hurdles for test statistics appropriate for a single test, we will very likely make a false discovery by virtue of having tested many hypotheses. Thus, the commonly used threshold of two for a t-statistic is too low. We describe the Bonferroni and Holm methods, which are both procedures to control the family-wise error rate or the probability of having at least one false discovery. With this groundwork in place, the next post will discuss ways in which to control the false discovery rate, which is arguably more suitable in the context of investments.
References
Holm, S., 1979. A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 6:65-70.
