
Since John Ioannidis published a paper in 2005 provocatively titled Why Most Published Research Findings are False, the general public and also researchers have gained a greater awareness of the unreliability of scientific discoveries based on “a single study assessed by formal statistical significance, typically for a p-value less than 0.05.” To be sure, scientists in fields such as genomics and others have long been aware of the need to adjust their hurdles for statistical significance to account for the very large number of tests they conduct. It would be fair to say, however, that general awareness of this issue has taken longer to develop in finance and economics, although some academics and practitioners were grappling with the issue of multiple testing years ago. It will probably take longer still for the retail investor who thinks running stock trading backtests on his online broker’s website makes him a trading “ninja.”
In the previous post we saw how multiple testing can lead to too many false discoveries unless we adjust the thresholds for significance. Methods that control the family-wise error rate (FWE), such as Bonferroni and Holm, ensure against false discoveries, but generally result in more missed discoveries than we would want in an investments context. In this post, I discuss an alternative approach introduced by Benjamini and Hochberg (1995) and Benjamini and Yekutieli (2001) that offers a way to increase power while maintaining some bound on false discoveries.
Let’s go back to the multiple testing problem. Recall the 2×2 table that counts the results of the M tests (and refer to the previous post for the detailed explanation).

Define the false discovery proportion (FDP) as 
The FDP gives the proportion of false discoveries to the total number of rejections. Now define the false discovery rate (FDR) as the expected value:

The idea is that by tolerating a small expected fraction of false discoveries we can get more power compared to the FWE approach, especially when M is large. More specifically, the objective is to control the false discovery rate below some small value 

To apply the Benjamini Hochberg Yekutieli (BHY) procedure, we start by ordering the p-values for the M tests such that


Now define the function 
Starting with the last test (k=M), we compare the p-value for each test 
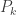
For example, if 



Note that BHY controls the expected FDP. It does not bound the number of false discoveries at 

Why does dependence between the tests matter? Consider the extreme case in which all the tests are perfectly correlated. Then we effectively only have one test so we would not need to adjust the p-value threshold. Thus far we have considered procedures for dealing with multiple testing that use only the collection of test statistics (the p-values). One advantage is that we often only have the p-values from someone else’s study and not the full data sets. However, as we have just seen, procedures that are valid under general dependence structures will usually have less power (and result in more missed discoveries). I won’t discuss this topic much in this post, but if we know the dependence structure we could use a procedure that controls the FDR, but has higher power. In practice, the dependence structure is unknown to us and must be estimated from the data via resampling the set of returns. White (2000) is one of the first to apply this approach to finance.
A related issue when examining studies done by others (or perhaps within your own shop if negative results are not tracked) is that of publication bias. For example, we may find 300 studies that report variables that forecast the cross-section of stock returns. However, there are many more studies that never got published since the results were not statistically significant even using unadjusted p-values. (Similarly, we may have a database of fund managers with survivorship bias.) Harvey, Liu, and Zhu (2014) make an ambitious attempt to adjust for these missing observations as well as the dependence structure of the tests. They conclude that a new variable forecasting the cross-section of returns in the US stock market would need to have a t-statistic of 3.0, which is far above the conventional threshold of two.
Furthermore the methods described in this post are based on looking at data in-sample. An alternative approach, often used in machine learning, is to use out-of-sample (or hold out) data to test a model after it has been trained on the in-sample data. This approach can be quite useful in certain contexts, but has some drawbacks. First, as I discussed in a previous post, data in finance and economics are rarely out-of-sample since we only have one realization of history, which we have already looked at. Second, if we split the data into in-sample and out-of-sample subsets we will have fewer observations in each compared to the entire sample. We can adjust the relative sizes of the in-sample and out-of-sample subsets, but will inevitably face a trade-off between false discoveries and missed discoveries.
A final comment, since this blog is intended to encompass discretionary as well as systematic perspectives, is that judgment and common sense are still key inputs into the investment process. Years ago, David Leinweber, as a joke, showed that butter production in Bangladesh was very closely associated with the S&P 500. Most seasoned investors would know better than to place much faith in such associations. However, the vastly larger datasets and more capable data mining techniques available today allow analysts to search for patterns at an unprecedented scale. As noted in a previous post, out-of-sample testing is often sloppy and in reality is thinly disguised in-sample testing. Even when out-of-sample data are truly out-of-sample, if you test enough hypotheses, some will look good both in-sample and out-of-sample purely by chance – a fact that you should be well aware of, having read this far. Lastly, not all hypotheses are equal before being confronted with data. Those that are based on economic theory should probably have a lower statistical hurdle to clear than purely empirical ones. Economic theories validated by out-of-sample data (that is, by data collected after a theory has been proposed) are more credible than theories constructed after looking at the data.
Summary
In this and the previous post, we have discussed the pervasive problem in finance (and other research fields) of false discoveries arising from multiple testing. We explained how methods such Benjamini, Hochberg, and Yekutieli (BHY) can control the false discovery rate as well as how extensions can improve power by estimating the dependence between tests or account for missing observations arising from publication or survivorship bias. Finally, we argued that statistical adjustments need to be used together with investment judgment. Serious investors will need to adopt these methods when developing trading strategies or evaluating portfolio managers in order to avoid discoveries that are bound to disappoint.
References
Benjamini, Y. and Y. Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society, 57.1, 289-300.
Harvey, C., Y. Liu, and H. Zhu. 2014. … and the cross-section of expected returns. Working paper, Duke University.
Ioannidis, J. 2005. Why most published research findings are false. PLoS Medicine.
Leinweber, D. 1995. Stupid data miner tricks: overfitting the S&P 500.
White, H. 2000. A reality check for data snooping. Econometrica, 68.5, 1097-1126.
Benjamini, Y. and D. Yekutieli. 2001. The control of the false discovery rate in multiple testing under dependency. The Annals of Statistics, 29.4, 1165-1188.
